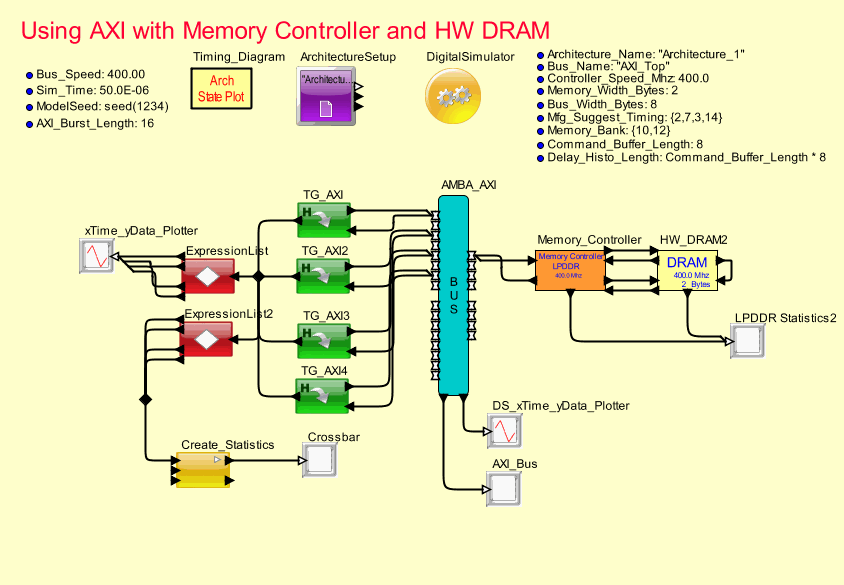
Modeling multiple requester with addresses to DDR and LPDDR
Launch Demo
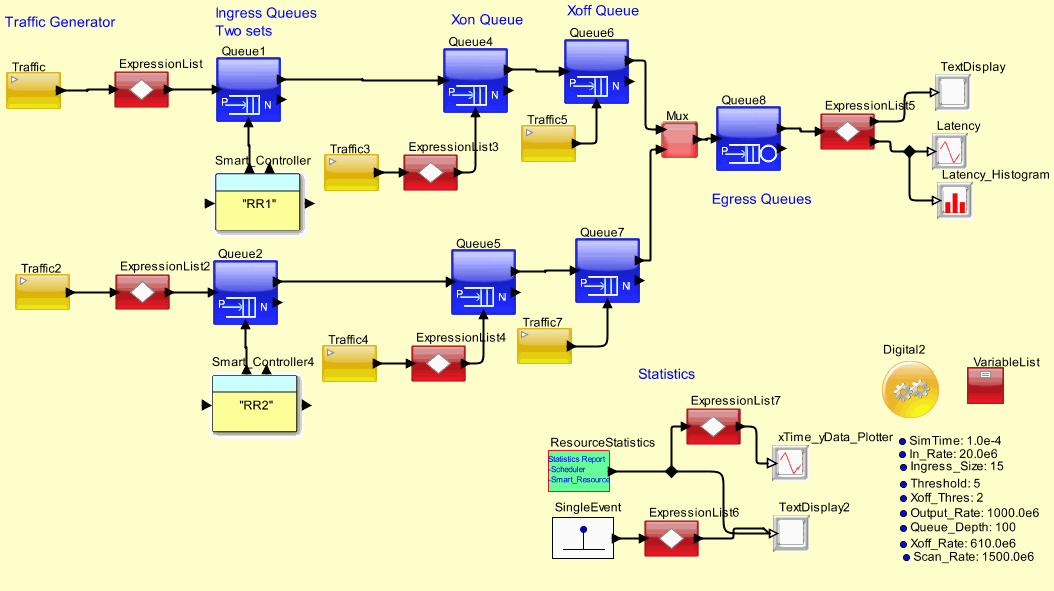
Credit-based arbitration for data movement from Ingress to Egress
Launch Demo
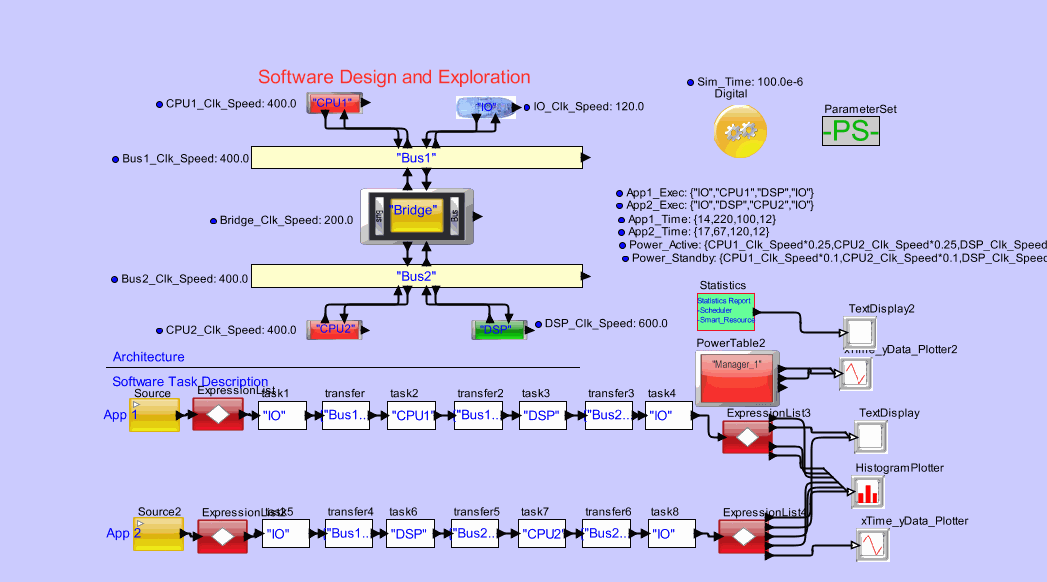
Model software processes as control and data-flow and map to hardware topology to study power and timing deadlines
Launch Demo
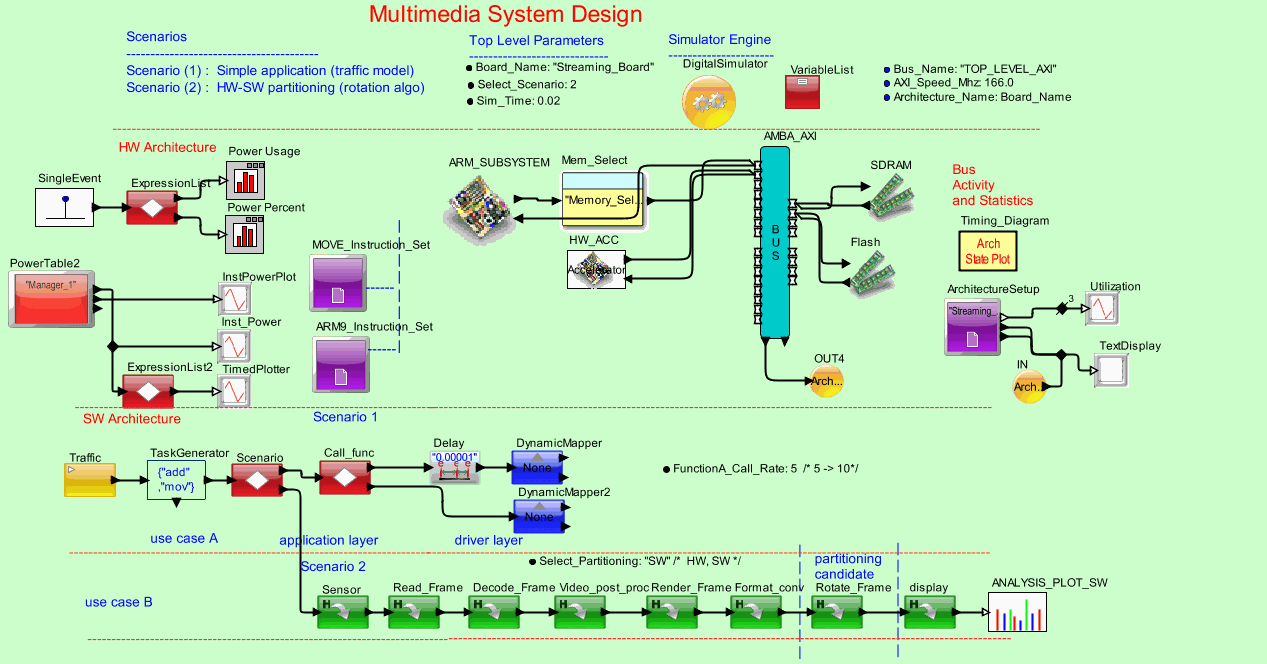
Exploring the implementation of a real-time video processing on a ARM SoC with hardware accelerators and power management
Launch Demo
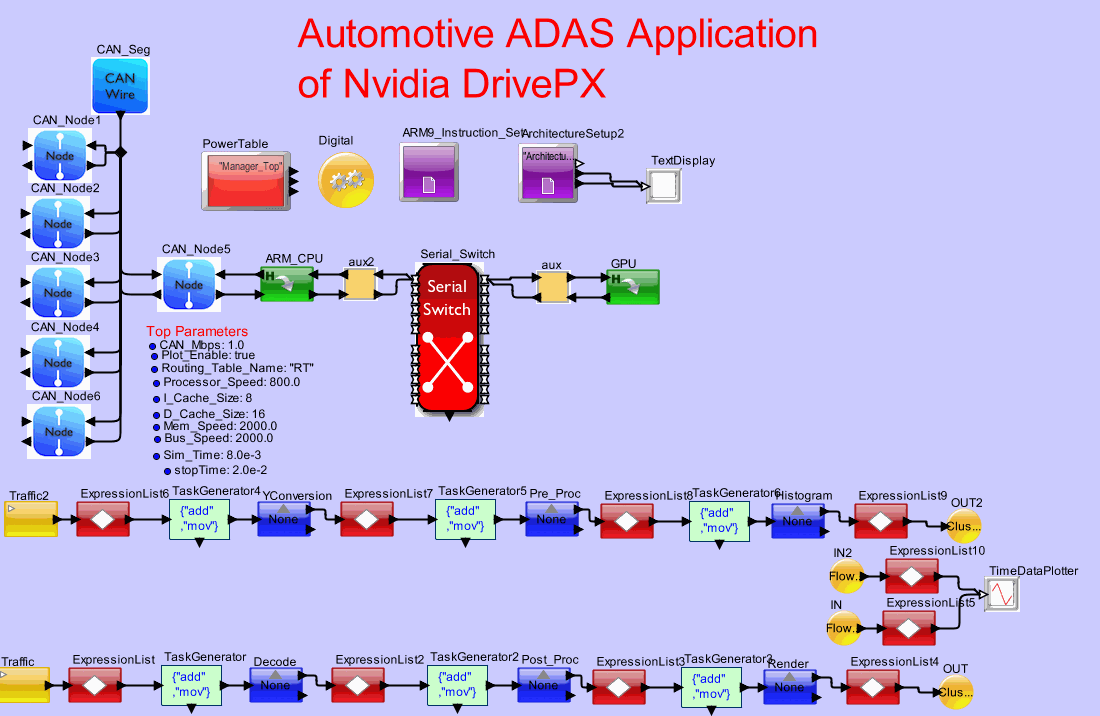
Drive-PX modeled with a CAN Network that is sending 4 Radar signals and 2 camera signals. The Drive-PX is modeled with the 4 ARM A72, 2 Denver and the GPU
Launch Demo
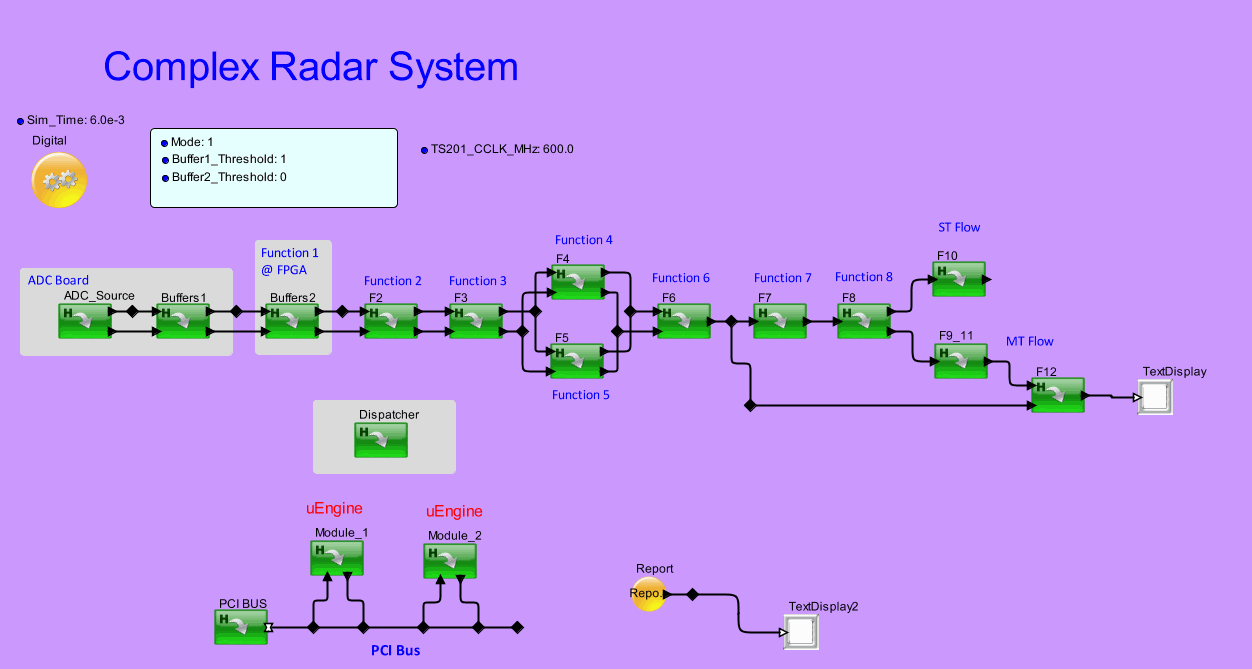
Hardware-software mapping of a Radar system for a aircraft.
Launch Demo
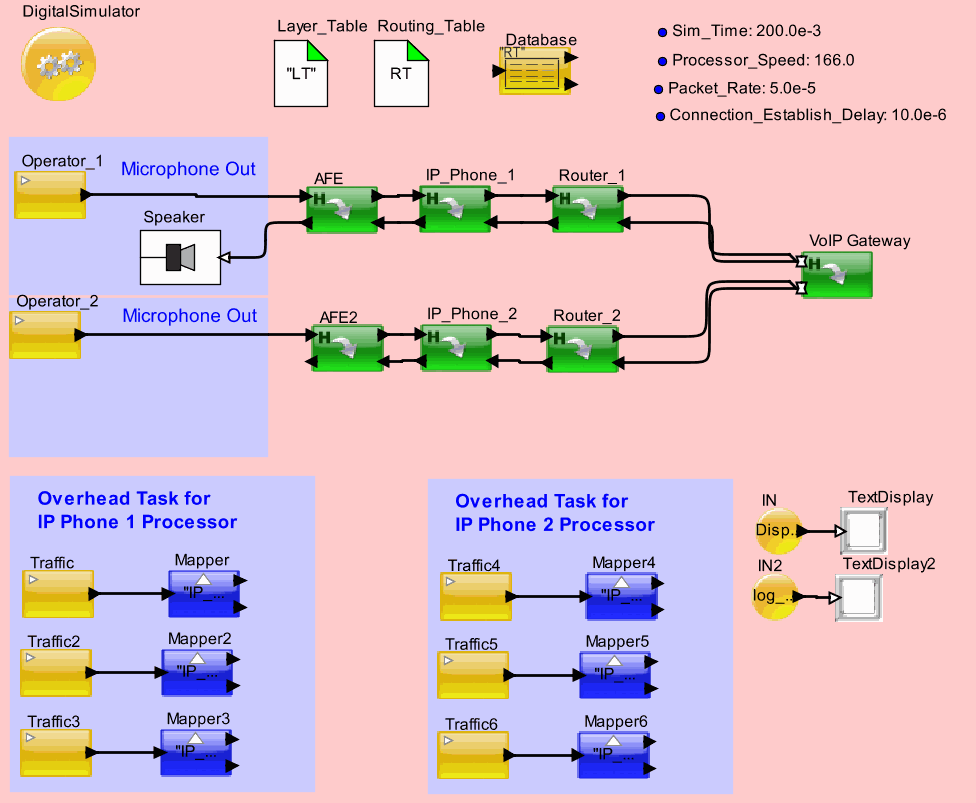
Designing the Routers and phones to meet quality and performance metrics
Launch Demo
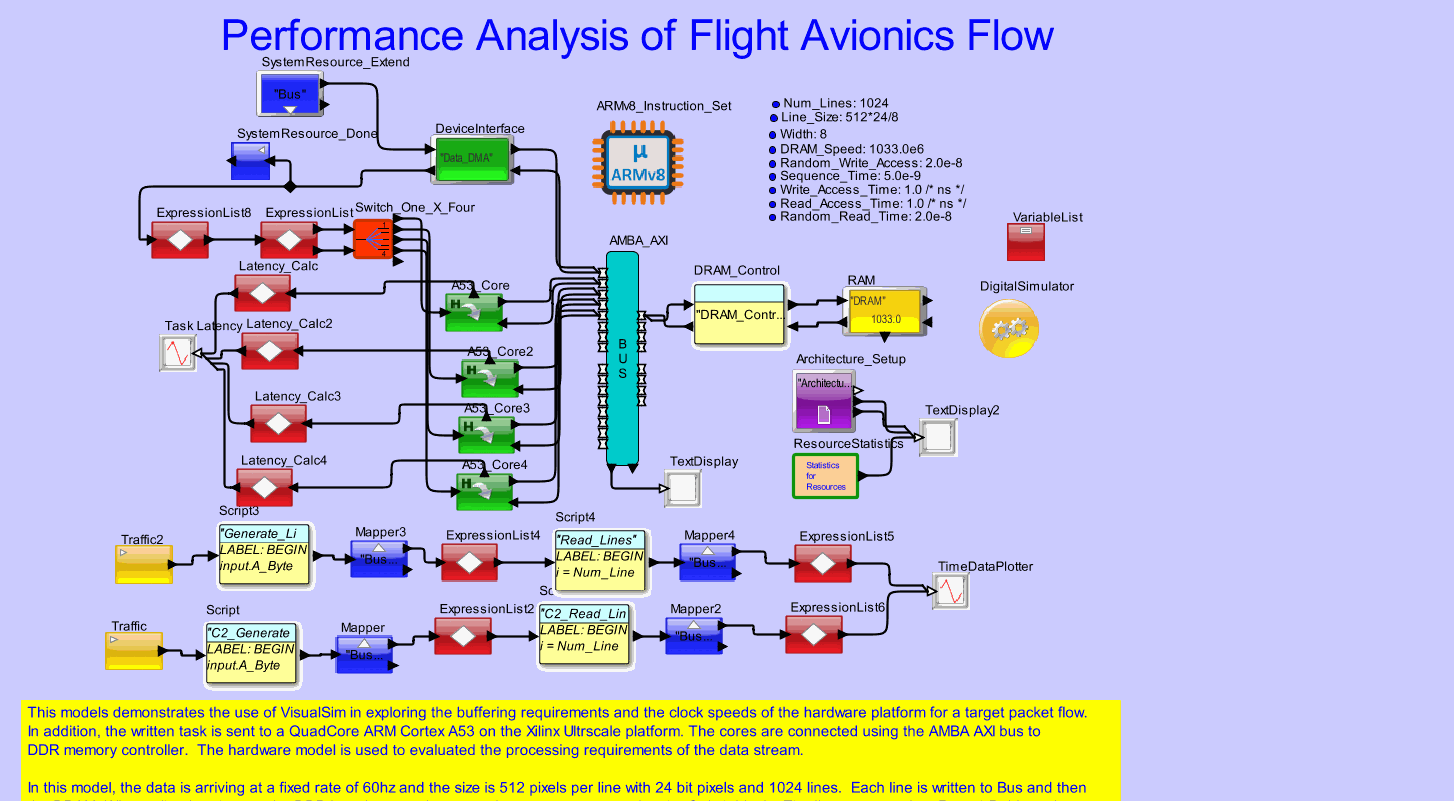
Implemented an avionics software on the Quadcore A53 on the Xilinx Ultrascale
Launch Demo
 SEAL- Interactive Training Modules▼
SEAL- Interactive Training Modules▼