
Deep Learning, Nvidia interpretation
Deep Learning Concept images

Back to server basics, Same Throughput with Fewer Server Nodes

To illustrate how throughput and cost savings are related, let’s assume there are two data centers. The CPU-Only data center is comprised of traditional CPU servers and the accelerated data center is comprised of a mix of traditional CPU servers and GPU-accelerated servers. Each node is dual-socket CPU design, while GPU-accelerated nodes have two NVIDIA Tesla V100 accelerators attached to the node. In terms of workload profile for both data centers, we’re assuming 70% of the jobs are based on app- lications that support GPU computing.
In this whitepaper, we’ll assume that a single CPU node can process one unit of work, or job, per day. So the CPU-Only data center has 1,000 nodes capable of processing 1,000 jobs.
Let’s take a look at the accelerated data center. Because 70% of jobs support GPU computing, 700 jobs in the queue can run on GPU-accelerated nodes while 300 jobs should run on CPU-only nodes. With a conservative assumption that GPU-enabled jobs run 20X faster on a Tesla V100 node compared to a CPU-only node, only 35 accelerated nodes are needed to deliver 700 jobs per day. 300 CPU nodes are required for the remaining jobs in the queue, for a total of 335 server nodes.
The accelerated data center delivers the same productivity with 67% less servers, racks, and networking equipment. This translates into tremendous savings in both acquisition cost as well as operation cost due to lower power and smaller physical space requirements.
Training and Inference for Data Centers
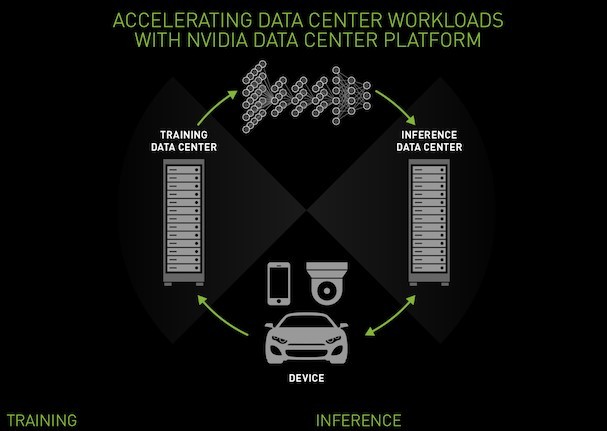
Training
Training increasingly complex models faster is key to improving productivity for data scientists and delivering AI services more quickly. Servers powered by NVIDIA® GPUs use the performance of accelerated computing to cut deep learning training time from months to hours or minutes.
Inference
Inference is where a trained neural network really goes to work. As new data points come in such as images, speech, visual and video search, inference is what gives the answers and recommendations at the heart of many AI services. A server with a single GPU can deliver 27X higher inference throughput than a single-socket CPU-only server resulting in dramatic cost savings.
Nvidia has committed resources to deep learning, while improving the performance of existing Data Centers using GPU accelerators, performance claims not-withstanding. Throughput and cost implications are examined. Inference is where a trained-set of neural layer weights are being processed, assumes learning period was sufficient. The training might continue with new inputs, such that new inferences might be generated, and the data center updated in after-hours?
VisualSim has some AI models, not necessarily in the production version of the tool. Check with Applications Engineering, if questions.
Web Reference: https://developer.nvidia.com/deep-learning


