
The on-chip bus plays a key role in the SoC design by enabling the efficient integration of system component’s like: CPU,DSP, application specific cores, memories and custom logic. As the level of design complexity has become higher, SoC designs require a system bus with high bandwidth to perform multiple operations in parallel. The multi-layer AHB bus matrix from ARM is one of the types of high-performance on-chip buses proposed. The ML-AHB bus matrix is an interconnection scheme based on the AMBA AHB protocol, which enables parallel access paths between multiple masters and slaves in a system.
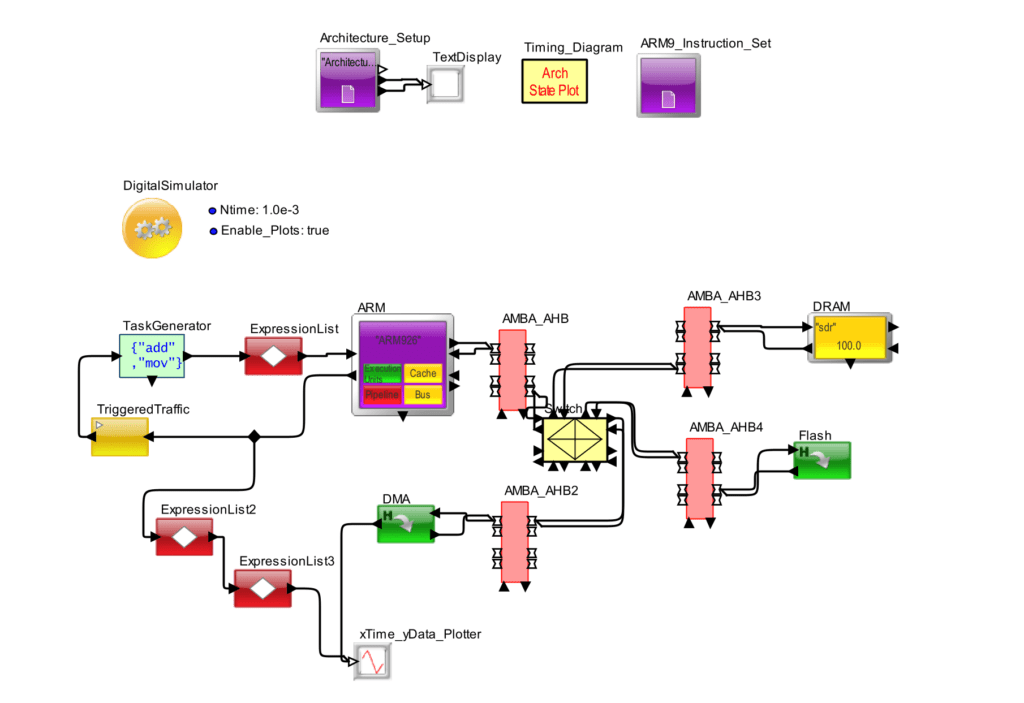
The ML-AHB bus matrix is an interconnection scheme based on the AMBA AHB protocol, which enables parallel access paths between multiple masters and slaves in a system. This is achieved by using a more complex interconnection matrix and gives the benefit of both increased overall bus bandwidth and a more flexible system structure.
However, the ML-AHB bus matrix of ARM presents only transfer-based arbitration schemes, i.e., transfer-based fixed-priority and round-robin arbitration schemes. This limitation on the arbitration scheme may lead to degradation of the system performance because the arbitration scheme is usually dependent on the Application requirements; recent applications are likewise becoming more complex and diverse. By implementing an efficient arbitration scheme, the system performance can be tuned to better suit applications.
The multi-layer AHB bus matrix (ML-AHB bus matrix) proposed by ARM is a highly efficient on chip bus that allows parallel access paths between multiple masters and slaves in a system. However, the ML-AHB bus matrix of ARM offers only transfer-based fixed-priority and round-robin arbitration schemes. In this paper, we present one way to improve the arbiter implementation of the ML-AHB bus matrix. When I had to design a model and implement the AMBA-AHB multi-layer bus-matrix, took the help of VisualSim Architect, since it provided various library blocks and had all the necessary functions as well. I could easily do the programming part too. One of the results which was achieved, was of the latency and data transfer where it’s very clear that as the latency increases he data transfer decreases.


